Generally, communication is one of the important things that humans needed. Much information can be extracted through a website or internet with mostly in natural language. The most issues when getting that information are ambiguous, messy words, or informal grammar.
Natural Language Processing (NLP) is one of AI that focuses on the human natural languages in order to read, understand, or extract the meaning of it.
Natural language is a language that generally used by humans for communication. Differently with the computer that has to process before understanding it.
By definition, natural language is one form message that allows communicators (sender) to communicate to communicants (receiver) through a media (like sound or text). NLP can be interpreted as a parser sentence that reads the sentence, word by word, and determined the next type of the word.
Area of Interest
There are several areas of interest in developing,
Question Answering Systems (QAS)
QAS gives the ability to answer questions that the user gave. Instead of searching in the search engine by keyword, the user can directly ask in natural languages.
Summarization
As the named, making a summary of a set of content. The application can help users convert large text documents into smaller forms without removing important information.
Machine Translation
As we know it can make the machine understand humans language then translate it into another language. For example Google Translate.
Speech Recognition
This field is a branch of NLP that quietly difficult. Well, some models for telephone or computer uses already a lot.
Document Classification
This is mostly used nowadays. The application can determine the inputted documents in the system to where should the document placed. We can meet it in spam filtering, news article classification, or even book reviews.
Finite State Automata
Finite State Automata (FSA) is a model of a collection of states in a given time. Let us make clear with the example. We know that nouns in English generally can be divided into two types; regular and irregular. Each of them can be a single or plural term. For each of the changes, we can make it as FSA:
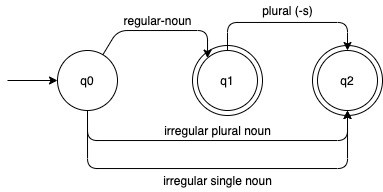
Noun FSA
Single arrow in the left determined an initial state. In this case, the state are q0, q1, and q2. The double circle is known as the final state. From that, we can conclude that noun can be:
- Regular single
- Regular plural based on a regular single (with suffixes -s, -es, …)
- Irregular single
- Irregular plural
Let us take one example more. This is one of the adjective’s FSA:
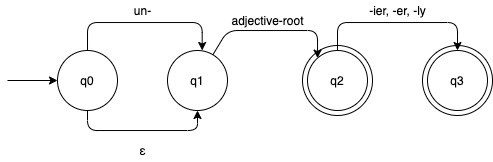
Adjective FSA
The epsilon (ε) means an empty string, nothing to input, or we can just skip it. From that FSA, we can conclude that adjective:
- It not only prefix (un-) or the empty string.
- Only base adjectives since ε can be skipped until the next state.
- Adjectives with the suffix.
Make it clear with the word:
- Clear, unclear, clearer, unclearly is an adjective if input to the FSA. But,
- Un-, ε (empty string), -ly is not an adjective.
Terminology
In terms of developing NLP, natural languages can be forms into a knowledge base. Three aspects to understand natural language,
- Syntax
Syntax explains the form of the language. The syntax can be specified by the grammar. It exceeds formal language in AI logic or computer program.
- Semantics
Semantics explains the meaning of the sentence. In building the NLP system for the application, it may use simple semantics representation.
- Pragmatics
Pragmatics explains the relationship or context not only in that sentence but also between the statement in the environment like the world, or purpose of the speaker.
Let’s us see several examples, let says we have four sentences:
- This article is about NLP.
- The blue bike display in the field.
- Colorless blue ideology fainting fast.
- Fainting fast ideology colorless blue.
First sentence suitable to place at the beginning of the article because its correctly in syntax, semantics, dan pragmatics. Second sentence correctly in syntax and semantics, but kinda bit weird if placed at the beginning of NLP article. Third sentence correctly in syntax but not in semantics. Last, it is not in syntax, semantics, and pragmatics.
Information Retrieval
Information Retrieval (IR) is the work of finding documents that are relevant to the user’s information needs. For example, the IR system that we have known is a search engine in the World Wide Web (WWW). Users can input any query in the form of text in a search engine and views the relevant result. These are characteristic of the IR system:
- A corpus of documents, every system must define the document used for. It can be a paragraph, page, or even multipage text.
- Queries posted in a query language, a query explains what is the user wants to get. Query language can be a list of characters or even specific phrases of adjacent words.
- A result set is a part of the document that defined as relevant to the queries.
- A presentation of the result set is the representation of the document result’s information in order to rank as a list.
Let's take a look simple diagram:
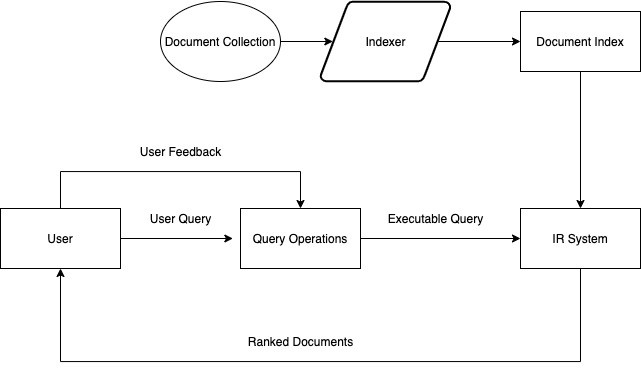
Process of IR System
Morphological Analysis
Morphological Analysis is the process that analyses individual word and token nonword like punctuation split from that word.
Say we have this sentence,
“I want to view Ilham’s .md file.”
We can use morphological analysis to that sentence,
- Split “Ilham’s” into the proper noun “Ilham” and possessive suffix “ ‘s “
- The sequence “.md” known as an extension file that used for adjective sentences.
The syntactic analysis uses the result from the morphological analysis for struct a description of the sentence. The final result is parsing. Parsing is a process to convert a list of words to the struct unit form.
Mostly system that used for syntactic processing has two primary components,
- Declarative representation, called grammar, syntactic fact about the language.
- The procedure, called parser, compare grammar with an inputted sentence for struct parsed sentence.
General way to grammar representation is a sequence of the production rules. For example, “Sentence includes a noun phrase followed by the verb phrase”.
The parsing process uses rule in the grammar, then compare to the inputted sentence. The most used parsing is Parse Tree. Every node relates to the inputted word or non-terminal in the grammar.
Example:
These are grammar like this:
- S → NP VP
- NP → the NP1
- NP → P
- NP1 → ADJS N
- ADJS → ε | small | long
- VP → V NP
- VP → V
- N → file | computer
- V → viewed | created | want
- P → Ilham
If we have a sentence like “Ilham viewed the file”, Parse Tree can be:
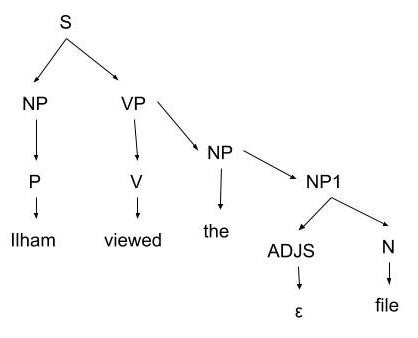
Simple Parsed Tree
Stemming
Stemming is a process that reduces variation that represented a word. The risk is the loss of certain information of stemmed words or decreases the accuracy. On the other side, stemming increases the ability to do recall.
The purpose of stemming is to increase performance and reduce uses of resources from the system with decreases count of the unique words. So in general, stemming algorithms do some transformation from word to standard morphology (known as stem).
Example:
Comput is stem of computable, compatibility, computation, computational, computed, computing, compute, computerize.
Lemmatization
Lemmatization is a process that finds the base form of the word (known as lemma). Even, there is a theory that lemmatization is the way to normalization text or word based on the base form.
Normalization is to identifying dan remove prefix or suffix from the word. So, lemma means a base form that has a certain meaning in the dictionary.
Example:
“The boy’s cars are different colors”
- Transformation: boy, boys, boy’s → boy
- Transformation: car, cars, car’s → car
- Transformation: am, is, are → be
- Transformation: different → differ
- Transformation: colors → color
Result: “The boy car be differ color”
Stemming and lemmatization have different algorithms for different languages.
Final Word
There are many things that are not covered in this article. But hopefully, this article can make a little bit of understanding the basics theories of NLP.
Note
This article is repost from my Medium Article